
仕事をしていて、あるファイルから特定の箇所を抽出したい。それが出来れば業務が早く終わるのに。でもやり方がわからないから手作業で行ってしまって、遅くなる、更に間違える。などよくあります。
また1からプラグラム組んでいたらプログラミングで時間を取られてしまった。などの経験があると思いますので、自分の好きな箇所の文字列を抽出していくpythonファイルの雛形を作成しておきます。
構成
まずはデフォルトのフォルダを決めて、そこにpythonファイルを作成します。同じフォルダに「text」フォルダ作成し、読み込むファイルと書き込むファイルを入れるフォルダにしましょう。

「text」フォルダには読み込むファイルを作成しておきましょう。ここでは「text_input.txt」としておきましょう。
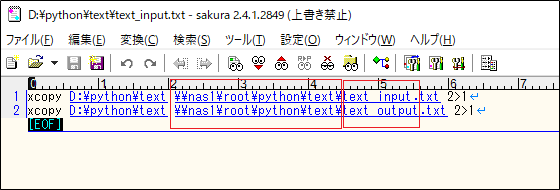
ファイルの中身は上記のようなコピーをしたようなログのファイルを準備して見ます。今回はここから「コピー先のパス」と「コピーしたファイル」を抽出してみましょう。
まずは何か共通点や一意のもの、特徴的なものなどを探します。今回はコピー先は「¥¥」で始まっています。ファイルは右から数えて最初の「.」が使用できそうですね。今回はこれにしましょう。
作成
ではひな形を作成しましょう!カタカタ肩
どどーーーん!
作成しました!!
path_input = "D:\\python\\text\\text_input.txt"
path_output_path = "D:\\python\\text\\text_output_path.txt"
path_output_file = "D:\\python\\text\\text_output_file.txt"
with open(path_output_file,"w") as f_o_f:
with open(path_output_path,"w") as f_o_p:
with open(path_input,"r") as f_i:
lines = f_i.readlines()
for line in lines:
start = line.index("\\\\")
end = line.rindex("\\")
url = line[start:end+1] + "\n"
f_o_p.write(url)
start_file = line.rindex("\\")
end_file = line.rindex(".")
url_file = line[start_file+1:end_file] + "\n"
f_o_f.write(url_file)結果:最終的にこうなれば成功です!
これを実行するとこうなります。
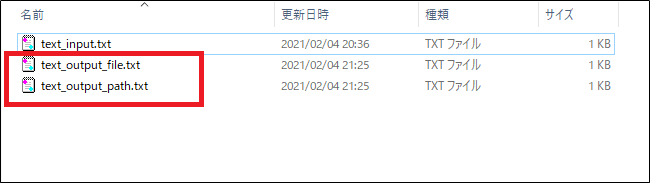
2つのファイルが出来ます。中身を見てみましょう!
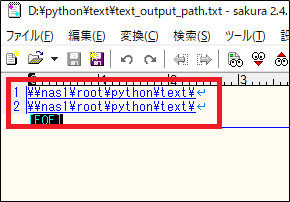
「text_output_path」ファイルを開いてみると、最初においていたファイルの中身からコピー後のファイルパスだけを抽出したファイルが出来ています。
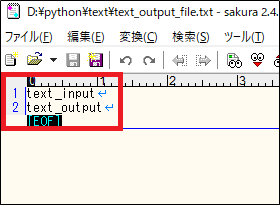
「text_output_file」ファイルを開いてみると、最初においていたファイルの中身からコピー後のファイル名だけを抽出したファイルが出来ています。
解説します。
path_input = "D:\\python\\text\\text_input.txt"#インプットするファイルパスを変数に入れましょう。
path_output_path = "D:\\python\\text\\text_output_path.txt"#アウトプットするパスのファイルパスを変数に入れましょう。
path_output_file = "D:\\python\\text\\text_output_file.txt"
#アウトプットするファイルのファイルパスを変数に入れましょう。
with open(path_output_file,"w") as f_o_f:
with open(path_output_path,"w") as f_o_p:
with open(path_input,"r") as f_i:ファイルを実際に読み込んでいきましょう。ファイルを書き込みで開いて変数「f_o_f」「f_o_p」に入れています。読み込むファイルは読み取り専用で開きましょう。「with」を使用し「:」で終わりインデントすると、インデント終わったところで自動で閉じてくれますので便利です。
withの注意
- スペースかタブでインデントしましょう。
- 行の最後に「:」を忘れずに入れましょう。
lines = f_i.readlines()「readlines」で読み取ったファイルを1行1行読み取っていき、リスト「lines」に入れます。
for line in lines:「for」で繰り返します。先程作成したリスト「lines」から一行ずつ取り出し変数「line」に入れます。
「for」注意点
- スペースかタブでインデントしましょう。
- 行の最後に「:」を忘れずに入れましょう。
start = line.index("\\\\")抽出する初めの位置を決め変数「start」に入れます。「index」メソッドで「¥¥¥¥」の位置を数えます。文字列の場合「¥」などはエスケープシークエンスなので「¥¥」と2回繰り返します。ここでは「¥¥」の位置が欲しいので「¥¥¥¥」と記入します。
end = line.rindex("\\")終わる位置は右から数えて最初の「¥」になるので「¥¥」とします。
url = line[start:end+1] + "\n"[]で囲う事で文字列から抽出してくれます。構文はこうです。
line[文字列の初めの位置:文字列の終わりの位置]
始めの位置は先程の「start」 終わりの位置は先程の「end」に1を足したものになります(初めが1ではなく0の為)最後に改行を表す「¥n」を「+」で足して変数「url」に入れましょう。
f_o_p.write(url)先程の変数「url」をwriteメソッドでファイルに書き込めば完了です。後はfor構文で最後の行まで繰り返してくれるのでOKです。
では同じ様にファイルも抽出して見て下さい。コードの残りの部分になります。
start_file = line.rindex("\\")
end_file = line.rindex(".")
url_file = line[start_file+1:end_file] + "\n"
f_o_f.write(url_file)読み込むファイルの共通点や特徴や独特な部分を見つける事が出来ればこれだけ覚えるだけでもかなり業務効率化が測れるのではないでしょうか。是非編集して作成して見て下さい。
